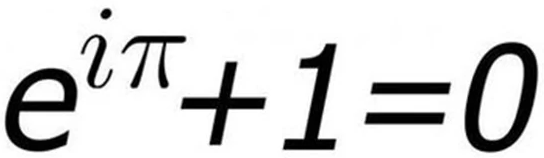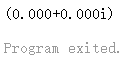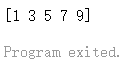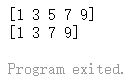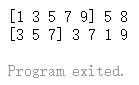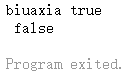Go语言开发环境搭建
go语言的安装
官网:https://golang.org ,但是需要富强才行。
Google 也在国内架设了镜像站点:https://golang.google.cn 。
如果镜像站点下载 Golang 也比较慢,可以使用国内社区镜像加速:https://studygolang.com/dl 。
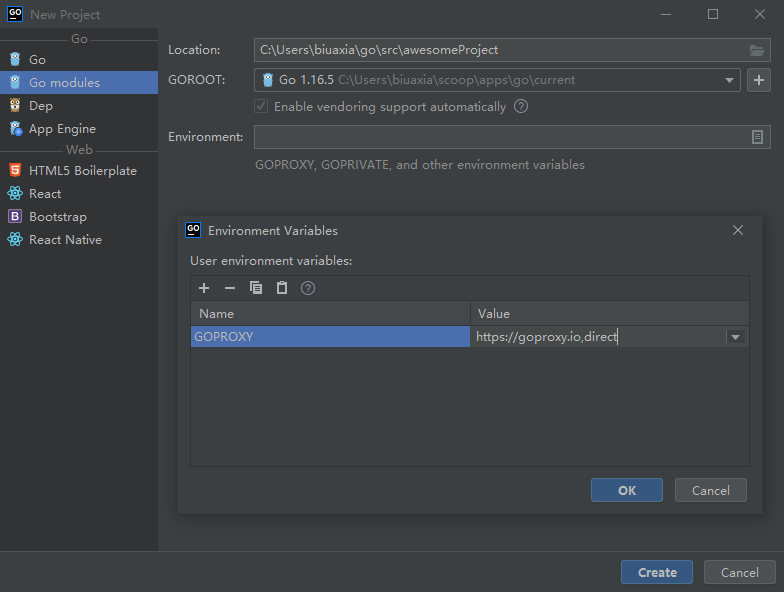
安装完了还需要配置 Golang 默认的代理用于加速 依赖包 的下载。
这里推荐两个代理地址:
上述的地址打开就可以看到具体如何使用 GOPROXY 了(建议复制,不要手动输入)。
goland的安装
下载地址:GoLand: A Clever IDE to Go by JetBrains ,打开较慢请打开富强或浏览器代理。
如果实在无法打开地址也可以从我的网盘下载:http://ddns.biuaxia.cn:8005/s/rnfE ,提取码ri03f3。
安装就和其他软件一样,一直下一步就可以了。
至于授权激活 Jetbrains 产品,可以参考我的另一篇文章《【转载】Jetbrains系列产品重置试用方法 - biuaxia 》。
安装后的界面是这样的:
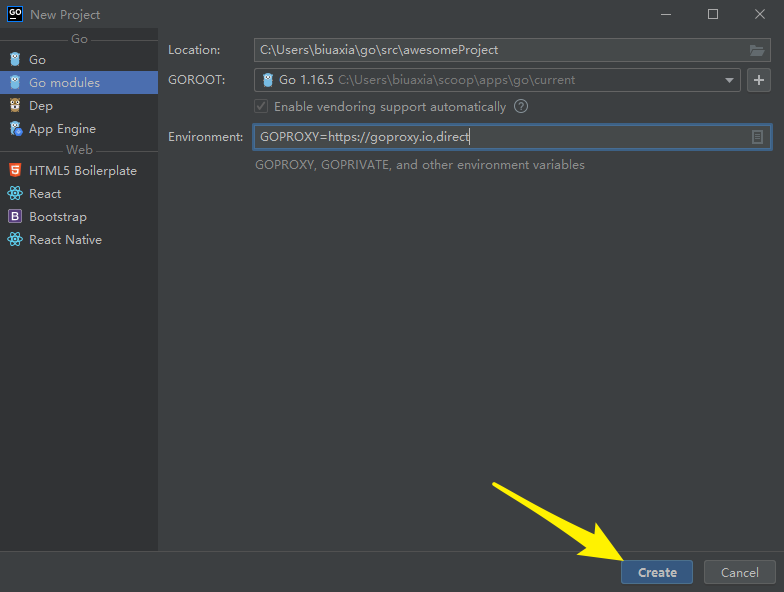
点击右上角的 New Project,修改 Localtion 的 awesomeProject 为你的项目名称。
Golang 的项目命名建议小驼峰命名,即首字母小写其余单词首字母大写。
或者你也可以通过修改 go.mod 实现 github.com/username/projectName 这种形式的命名(实际项目名称不影响)。
配置好项目的环境变量,点击 Create 完成项目创建。
注意:上面的配置仅针对项目起作用,全局的 Go 并未应用此 GOPROXY配置。
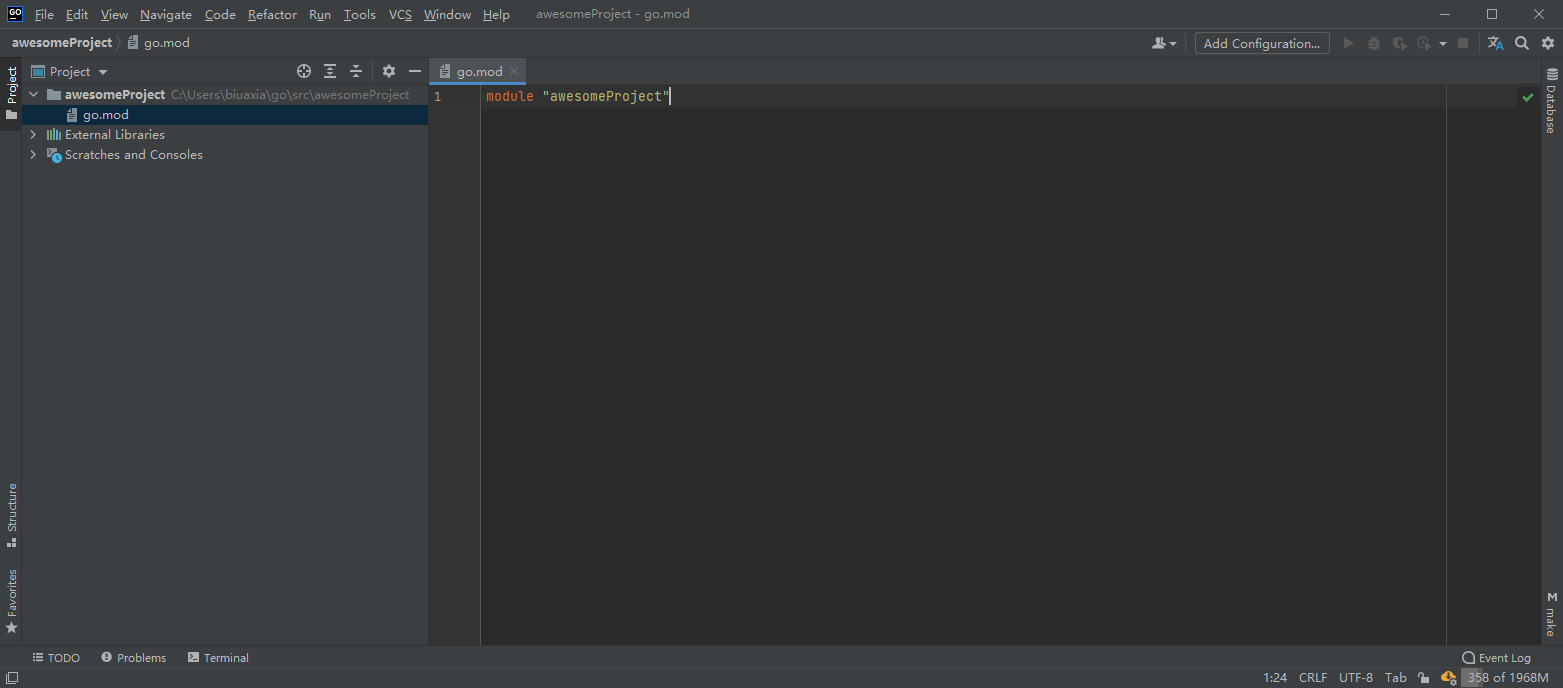
项目加载完毕,可以打开 go.mod 查看内容。
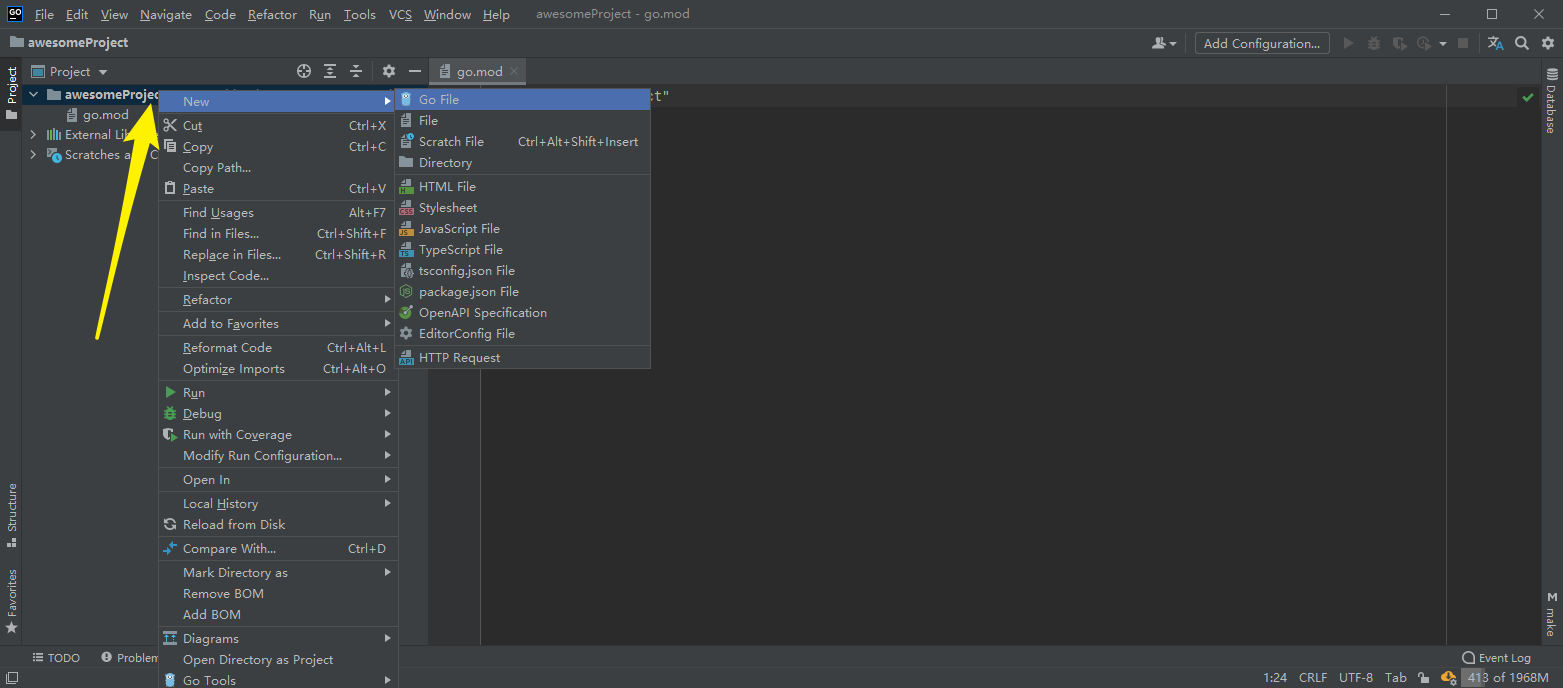
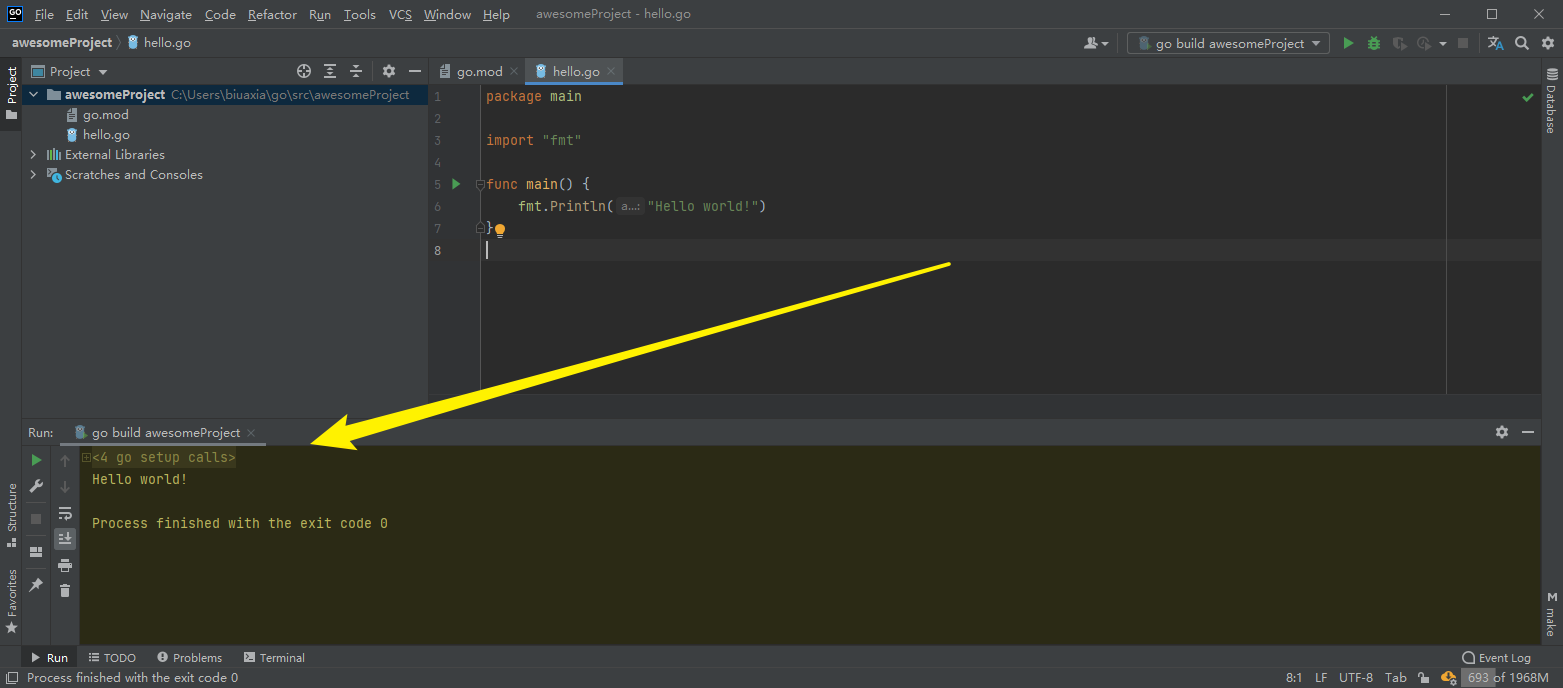
编写第一个 go 程序,在Project窗口下右键项目名称新建 Go File。
弹出的窗口选择 Simple application。
内容为:
1 2 3 4 5 6 7 package mainimport "fmt" func main () "Hello world!" )
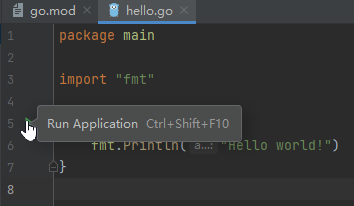
左键单击小手位置的 ▶ 选择 Run go build ... 以运行 Go 程序。
黄颜色的区域就是运行结果的输出区域,又叫 控制台,后面程序的输出等内容基本都在这里。
还需要对 Goland 做一些配置。
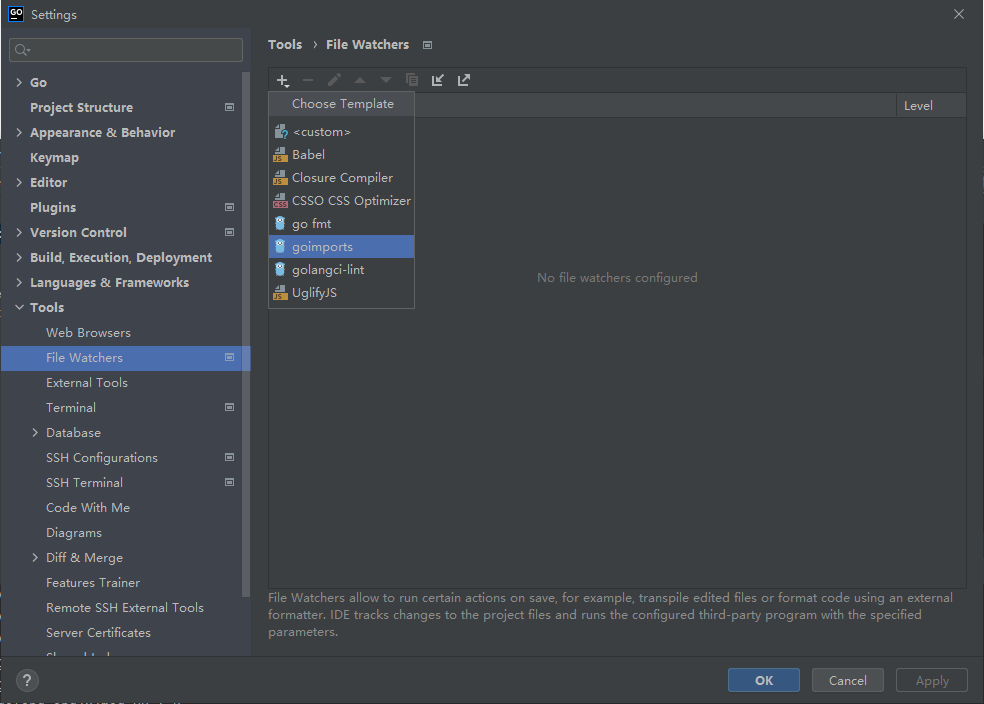
File Watcher
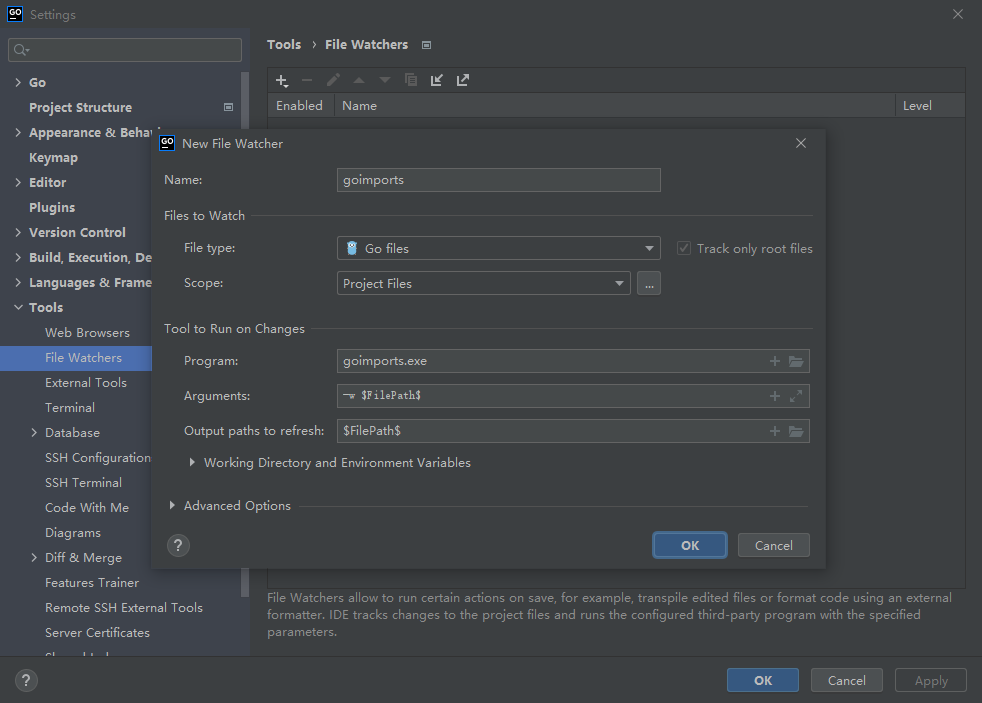
需要增加 goimports,用来实现自动导入和格式化。
配置路径为: File | Settings | Tools | File Watchers
如果没有下载,请在命令行执行:go get golang.org/x/tools/cmd/goimports
点击 OK 就行了。
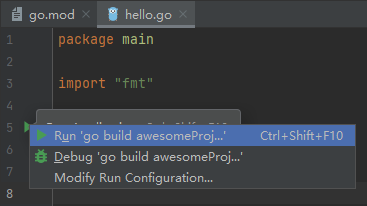
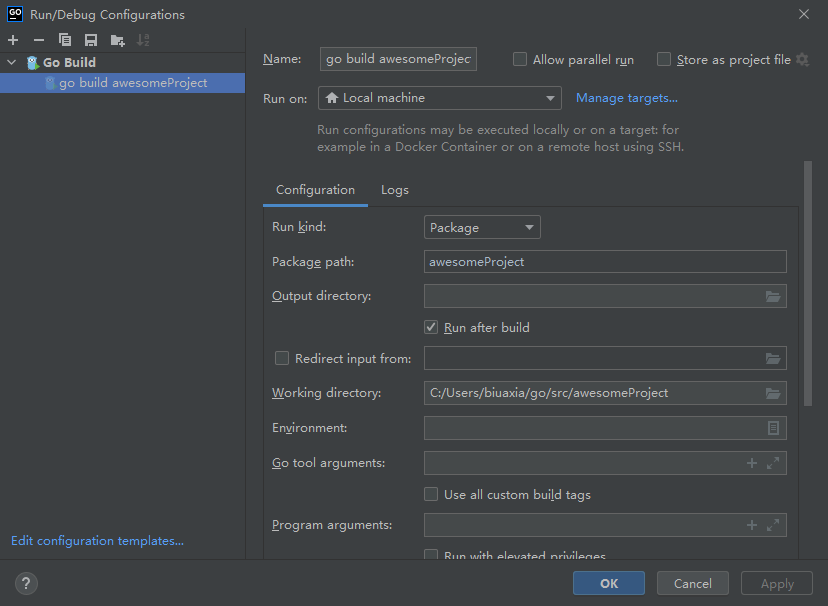
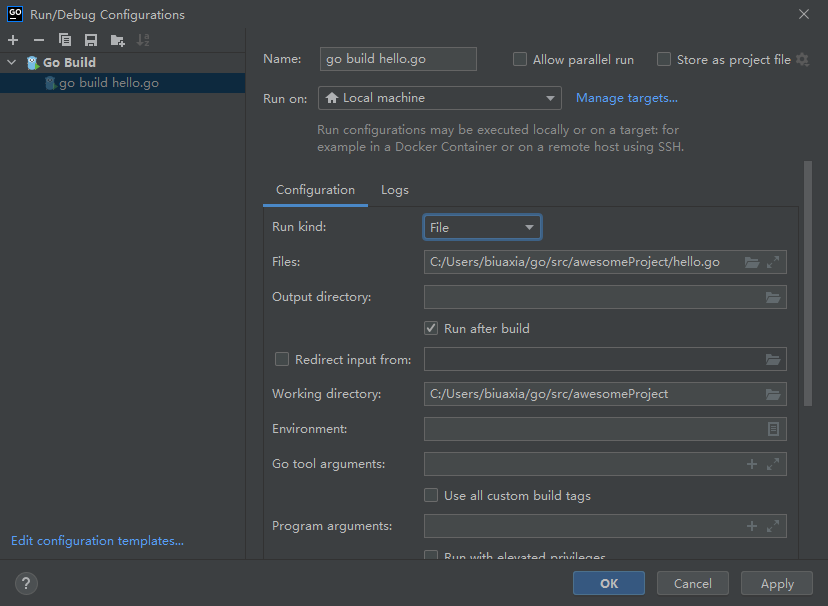
运行方式的配置(无法运行程序也可以这样修改试试)
修改 Configuration 中的 Run kind 为 File,如图
就可以了。
Go基础语法
变量定义
简单的变量定义方法:
1 2 3 4 5 6 7 8 9 package mainimport "fmt" func main () var a int var b string "%d %q\n" , a, b)
声明变量不赋值那么变量就是对应类型的初值(例如 int 就是 0,string 就是 空字符串 “”,可以使用 %q 输出),并且演示了 golang 中的占位输出 fmt.Prinf 函数,进一步了解占位符可以查看《【转载】Go语言fmt.Printf使用指南(占位符总结) - biuaxia 》。
声明变量的同时赋初值:
1 2 3 4 5 6 7 8 package mainimport "fmt" func main () var a,b int = 1 , 2
同时声明相同类型的变量可以在同一行通过 var 变量1, 变量2, ... 类型 = 初值1, 初值2, ... 这种形式。
注:变量声明就必须使用!
类型推断:
1 2 3 4 5 6 7 8 package mainimport "fmt" func main () var a, b, c = 1 , "string" , true
可以省略 类型 的显式表达,并且声明行的类型可以是不同类型,例如上面的 a, b, c 就是 int, string, bool。
简短声明:
1 2 3 4 5 6 7 8 9 10 package mainimport "fmt" func main () 1 , "s" , true 2
声明时候的 var 也可以省略,但是当前函数如果对变量重新赋值就只能使用 =,不能使用 :=。
建议定义变量使用简短声明,即省略 var 关键字 和 类型的显式表达。:= 只能在函数内使用,函数外不能使用。
函数外的变量定义注意事项
函数外定义变量只能使用下面的方式:
var 变量名 类型,声明不赋值var 变量名 = 内容,声明且赋值
不能使用 变量名 := 内容 这种简短声明。
并且函数外定义的变量作用域为对应的 package,即 package 作用域内的 全局变量。
且声明的变量 可以不使用,没有函数内定义的变量必须使用这种强制要求。
集中定义变量
不论是在函数外或是在函数内,声明变量都可以使用 var() 批量声明,声明的同时也可以赋值:
1 2 3 4 5 6 7 8 9 10 11 12 13 package mainimport "fmt" var (1 "k" true func main ()
内建变量类型
bool, string
(u)int, (u)int8, (u)int16, (u)int32, (u)int64, uintptr
byte, rune
float32, float64, complex64, complex128
带有 (u) 标识的表示 加u就是无符号整数,不加u就是有符号整数。
有符号整数还分为两类,规定长度和不规定长度(根据操作系统决定,即32位操作系统就是32位,64就是64这种)。
uintptr 就是 go 语言中的指针,指针的长度和不规定长度的整数一样,根据操作系统决定。
byte 字节,rune 字符,即其它语言的 char 类型。rune 实际是 int32,byte 实际是 int8。他们就是整数的别名,是可以混用的。
complex 复数。
使用复数
1 2 c := 3 + 4i
使用 go 实现 欧拉公式 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ("fmt" "math" "math/cmplx" func euler () 1i *math.Pi) + 1 func main ()
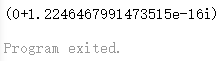
运行结果为:
这里的结果不是0,是因为 complex64 它的实部和虚部都是 float32,complex128 实部和虚部都是 float64。任何一个语言遵循了浮点数标准它运算出来的结果都是不精确的。
还可以使用自带的函数省略掉 math.E 的声明。
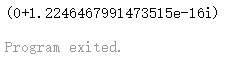
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ("fmt" "math" "math/cmplx" func euler () 1i *math.Pi) + 1 func main ()
运算结果也是一样的:
可以通过格式化输出来得到 0 的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ("fmt" "math" "math/cmplx" func euler () 1i *math.Pi) + 1 "%.3f\n" , r)func main ()
运行结果为:
强制类型转换
Go语言中的类型转换是强制的,没有隐式类型转换。
例如:
1 2 3 4 5 6 7 8 9 10 11 12 package mainimport ("fmt" "math" func main () 3 , 4
运行会提示:
1 ./main.go:10:21: cannot use a * a + b * b (type int) as type float64 in argument to math.Sqrt
显式转换类型后才能运行:
1 2 3 4 5 6 7 8 9 10 11 12 package mainimport ("fmt" "math" func main () 3 , 4 float64 (a*a + b*b))
常量与枚举
常量定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package mainimport ("fmt" "math" const url = "http://qq.com" const ("ofd" "pdf" func main () const a = "str" const b, c = 3 , 4 const e = 233
基本和变量定义是一样的用法,只是没有简短声明 :=。
常量声明了可以不使用,例如函数作用域的e
常量参与运算会自动推断类型,例如math.Sqrt 运算时并未强制类型转换(const 显示声明类型除外)。
枚举类型
在Go语言中可以通过下面的方式实现枚举:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package mainimport "fmt" const (0 1 2 3 4 func main ()
还可以通过使用 iota (它表示定义的元素是自增值的)来省略常量有规则的赋值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package mainimport "fmt" const (iota func main ()
运行结果都是一致的。
iota 还可以跳过某个值,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package mainimport "fmt" const (iota func main ()
结果为:0 2 3 4。
iota 还可以参与运算:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport "fmt" const (1 << (10 * iota )func main ()
运行结果为:1 1024 1048576 1073741824 1099511627776 1125899906842624。
iota 作为自增值的种子,只要能写出表达式对应的值都将被定义出来。
条件语句
if
if 的条件里可以赋值:
1 2 3 4 5 if content, err = ioutil.ReadFile("a.txt" ); err == nil {else {"err: " , err)
if 的条件里赋值的变量作用域就在这个 if 语句里。
switch
switch 会自动 break,除非使用 fallthrough。
switch 关键字后可以没有表达式,在 case 捕获条件就行了。
循环
for
for 的条件不需要括号。
for 的条件里可以省略初始条件,结束条件,递增表达式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package mainimport ("fmt" "strconv" func getBinary (n int ) string ) {for ; n > 0 ; n /= 2 {2 )return func main () 1 ))13 ))
运行结果为:
while
go 语言中没有 while,可以使用 go 来替代 while。
1 2 3 4 5 6 7 8 9 for n > 0 {"n > 0" )for {"abc" )
函数
函数返回多个值时可以起名字(仅用于非常简单的函数)。
复合函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport ("fmt" "math" "reflect" "runtime" func apply (op func (int , int ) int , a, b int ) int {"函数#%s被调用,入参: [%d, %d]\n" return op(a, b)func pow (a, b int ) int {return int (math.Pow(float64 (a), float64 (b)))func main () 3 , 4 ))
运行结果为:
上面调用传入的 pow 会比较难理解,改写成下面的形式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport ("fmt" "math" "reflect" "runtime" func apply (op func (int , int ) int , a, b int ) int {"函数#%s被调用,入参: [%d, %d]\n" return op(a, b)func main () func (a, b int ) int {return int (math.Pow(float64 (a), float64 (b)))3 , 4 ))
运行结果为:
可以看到函数名出现了变化。
可变参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ("fmt" func sum (nums ...int ) int ) {for _, i := range nums {return func main () 1 , 2 , 3 , 4 , 5 , 6 ))
运行结果为:21。
指针
简单使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ("fmt" func swap (a, b *int ) func main () 1 , 2
一般通过函数返回再接收的方式处理这种换值的情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ("fmt" func swap (a, b int ) int , int ) {return b, afunc main () 1 , 2
* 表示指针,& 表示对取值。这两个是结对出现的。
内建容器
数组
定义、指定长度、赋初值、推断长度、二维数组的使用方式(可以和变量的简短声明套用):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package mainimport "fmt" func main () var arr [5 ]int var arr1 = [3 ]int {1 , 3 , 5 }int {1 , 2 , 3 , 4 }4 ][5 ]int {1 , 2 , 3 , 4 , 5 },11 , 22 , 33 , 44 },111 , 222 },
运行结果为:
遍历数组
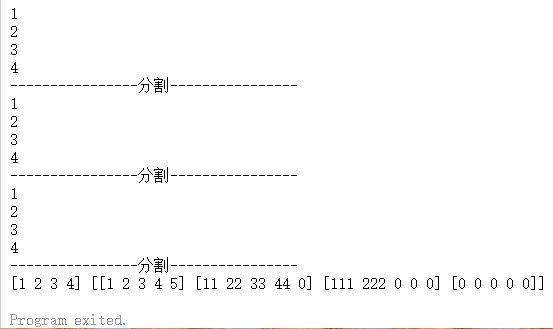
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package mainimport "fmt" func main () int {1 , 2 , 3 , 4 }4 ][5 ]int {1 , 2 , 3 , 4 , 5 },11 , 22 , 33 , 44 },111 , 222 },for i := 0 ; i < len (arr1); i++ {"----------------分割----------------" )for i := range arr1 {"----------------分割----------------" )for _, v := range arr1 {"----------------分割----------------" )
运行结果为:
可以通过_ 省略变量
不仅range ,任何地方都可以通过_ 省略变量
如果只要 i,可以写成for i := range arr
为什么要用 range
意义明确,美观
数组是值类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport "fmt" func change (arr [4]int ) 0 ] = 100 func main () int {1 , 2 , 3 , 4 }
函数改变了 0 下标的元素,但实际上并未改变;即值传递(拷贝一份)。
修改为指针后就能够实现修改了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport "fmt" func change (arr *[4]int ) 0 ] = 100 func main () int {1 , 2 , 3 , 4 }
Go 语言使用数组还需要提前知道长度。一般不使用数组和数组指针,而是使用切片。
切片的概念
定义:
1 2 3 4 5 6 7 8 9 10 11 package mainimport "fmt" func main () int {1 , 2 , 3 , 4 , 5 , 6 }1 :])3 ])1 :3 ])
切片实际是数组的一个 View(视图)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport "fmt" func updateSlice (s []int ) 0 ] = 100 func main () int {1 , 2 , 3 , 4 , 5 , 6 }1 :])3 ])1 :3 ])1 :]3 ]
运行结果为:
可以看出切片是底层数组的视图以及引用传递。
ReSlice
切片再切片:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport "fmt" func updateSlice (s []int ) 0 ] = 100 func main () int {1 , 2 , 3 , 4 , 5 , 6 }1 :]3 ]2 :3 ]
运行结果为:
上面的 arr 其实都是底层数组的 View 视图,所以 arr3 能够拿到值,而非下标越界报错。
切片的操作
向 Slice 添加元素
1 2 3 4 5 6 7 8 9 10 11 12 13 package mainimport ("fmt" func main () int {1 , 2 }append (arr1, 3 )append (arr2, 4 )
添加元素时如果超越源数组的cap容量,系统将会重新分配更大的底层数组。
原来的数组如果没有使用就被垃圾回收。
由于值传递的关系,append 必须接收其返回值。s = append(s, val)
切片的声明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ("fmt" func main () var arr []int for i := 0 ; i < 5 ; i++ {append (arr, 2 *i+1 )
Slice 声明出来不赋值就是 nil,但是也可以使用 append 进行元素的追加。
还可以指定切片长度:
也可以长度和容量一起指定:
1 arr := make ([]int , 5 , 10 )
拷贝切片
系统有一个 copy 函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package mainimport ("fmt" func main () var arr []int for i := 0 ; i < 5 ; i++ {append (arr, 2 *i+1 )make ([]int , 2 )copy (arr1, arr)
copy函数即将 arr 拷贝至 arr1。
如果 arr1 是使用 var arr1 []int 声明的方式定义,再使用 copy 将不会被拷贝。
如果是上面的代码一样目标数组(arr1)小于被拷贝数组(arr)将只拷贝最前的元素,
删除元素
例如删除切片中下标为 2 的元素:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ("fmt" func main () var arr []int for i := 0 ; i < 5 ; i++ {append (arr, 2 *i+1 )append (arr[:2 ], arr[3 :]...)
删除 头部 & 尾部 元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport ("fmt" func main () var arr []int for i := 0 ; i < 5 ; i++ {append (arr, 2 *i+1 )len (arr), cap (arr))0 ]1 :]len (arr)-1 ]len (arr)-1 ]len (arr), cap (arr), front, tail)
可以看到 append 有时候会改变 cap 容量。
Map
定义 map:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package mainimport ("fmt" func main () map [int ]string {1 : "1" ,2 : "2" ,3 : "3" ,make (map [string ]int )var m2 map [string ]int
注意make出来的是空的map,而不是 nil。仅定义不赋值的是 nil。
遍历 Map
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package mainimport ("fmt" func main () map [string ]string {"course" : "java" ,"author" : "biuaxia" ,"site" : "google" ,for k, v := range m {
还需要注意每次运行输出的结果不一致:
获取指定 Key 的 value 和判断元素是否存在:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport ("fmt" func main () map [string ]string {"course" : "java" ,"author" : "biuaxia" ,"site" : "google" ,"%q\n" , m["course" ])"%q\n" , m["java" ])if value, ok := m["java" ]; ok {"存在" )else {"不存在" )
删除元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport ("fmt" func main () map [string ]string {"course" : "java" ,"author" : "biuaxia" ,"site" : "google" ,"author" ]delete (m, "author" )"author" ]
map的操作总结如下:
创建:make(map[string]int)
获取元素:m[key]
key不存在时,将会获得 Value 类型的初始值
用 value, ok := m[key] 来判断是否存在 key
使用 range 遍历 key,或者遍历 key, value 对
不保证遍历顺序,如需顺序需要手动对 key 排序
使用 len 获得元素个数
map 的 key
map 使用哈希表,必须可以比较相等
除了 slice,map,function 的内建类型都可以作为 key
Struct 类型不包括上述字段也可以作为 key
Map例题
寻找最长不含有重复字符的子串。来自 Leetcode,参见:Longest Substring Without Repeating Characters - LeetCode 或 剑指 Offer 48. 最长不含重复字符的子字符串 - 力扣(LeetCode) 。
即:
abcabcbb -> abc
bbbbb -> b
pwwkew -> wke
对于每一个字母 x:
lastOccurred[x] 不存在,或者< start 则无需操作
lastOccurred[x] >= start 则更新 start
更新 lastOccurred[x],更新 maxLength
具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport "fmt" func lengthOfNonRepeatingSubStr (s string ) int {make (map [byte ]int )0 0 for i, ch := range []byte (s) {if ok && lastI >= start {1 if i-start+1 > maxLength {1 return maxLengthfunc main () "abcabcbb" ))"bbbbb" ))"pwwkew" ))"中文哈哈" ))
这里没有处理字符串为非 ASCII (美国信息交换标准代码)的情况。
字符和字符串处理
rune 相当于 golang 的 char。
1 2 3 4 func main () "撒大苏打" len (s))
居然是12,而不是4?
再次修改程序:
1 2 3 4 5 6 7 8 9 10 11 func main () "小度xiaodu" for _, b := range []byte (s) {"%X " , b)for i, ch := range s {"(%d %X)" , i, ch)
使用系统自带的 "unicode/utf8" 库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport ("fmt" "unicode/utf8" func main () "小度xiaodu" byte (s)for len (bytes) > 0 {"%c " , ch)
直接使用 rune 数字转换字符串就能达到想要的效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport ("fmt" "unicode/utf8" func main () "小度xiaodu" byte (s)for len (bytes) > 0 {"%c " , ch)for i, ch := range []rune (s) {"(%d %c)" , i, ch)
使用 range 遍历 position,rune 对(但这样遍历 position 不是连续的)
使用 utf8.RuneCountInString 获得字符数量
寻找最长不含有重复字符的子串(国际版)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package mainimport ("fmt" func lengthOfNonRepeatingSubStr (s string ) int {make (map [rune ]int )0 0 for i, ch := range []rune (s) {if ok && lastI >= start {1 if i-start+1 > maxLength {1 return maxLengthfunc main () "abcbb" ))"一二三三二一" ))"面向对象面向程序面向对象" ))
有关字符串相关的操作,碰到了可以先去 "strings." 去找找。
Fields,Split,JoinContains,IndexToLower,ToUpperTrim,TrimRight,TrimLeft
等常用的 strings 包方法。
面向“对象”
结构体和方法
结构体的简单定义:
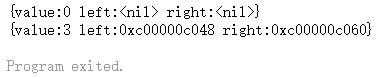
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package mainimport ("fmt" type TreeNode struct {int func main () var root TreeNode"%+v\n" , root)3 }5 , nil , nil }new (TreeNode)"%+v\n" , root)
运行结果为:
不论地址还是结构本身一律使用 . 来访问成员。
配合 Slice 使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport ("fmt" type TreeNode struct {int func main () var root TreeNode3 },6 , nil , &root},"%+v\n" , nodes)
运行结果为:
使用自定义工厂函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport ("fmt" type TreeNode struct {int func createTreeNode (value int ) return &TreeNode{Value: value}func main () var root TreeNode"%+v\n" , root)3 }5 , nil , nil }new (TreeNode)2 )"%+v\n" , root)
运行结果为:
注意 createTreeNode 方法返回了局部变量的地址。
为结构体定义方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport ("fmt" type TreeNode struct {int func createTreeNode (value int ) return &TreeNode{Value: value}func (node TreeNode) print () {func main () var root TreeNode3 }5 , nil , nil }new (TreeNode)2 )print ()
运行结果为:
指针调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package mainimport ("fmt" type TreeNode struct {int func createTreeNode (value int ) return &TreeNode{Value: value}func (node TreeNode) print () {func (node *TreeNode) int ) {func main () var root TreeNode3 }5 , nil , nil }new (TreeNode)2 )print ()4 )print ()
运行结果为:
不管是 print 值接收者还是 setValue 指针接收者,都可以拿到结构具体的值去调用。
只是调用 print 会拷贝一份 node,而调用 setValue 会将 node 的地址给到调用方法。
为了验证,将 root 的地址拷贝到 pRoot 做验证:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package mainimport ("fmt" type TreeNode struct {int func createTreeNode (value int ) return &TreeNode{Value: value}func (node TreeNode) print () {func (node *TreeNode) int ) {func main () var root TreeNode3 }5 , nil , nil }new (TreeNode)2 )print ()4 )print ()print ()200 )print ()print ()
结果为:
显式定义和命名方法接收者
使用指针作为方法接收者
只有使用指针才可以改变结构内容。
接收者允许为 nil 指针。
实现遍历结构体
遍历 TreeNode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package mainimport ("fmt" type TreeNode struct {int func createTreeNode (value int ) return &TreeNode{Value: value}func (node TreeNode) print () {" " )func (node *TreeNode) int ) {if node == nil {"setting value to nil node. Ignored." )func (node *TreeNode) if node == nil {return print ()func main () var root TreeNode3 }5 , nil , nil }new (TreeNode)2 )4 )
运行结果为:
如何判断使用值接收者还是指针接收者
要改变内容必须使用指针接收者。
结果过大也考虑使用指针接收者(避免拷贝影响性能)。
一致性 :如果有指针接收者,最好都是指针接收者。
值接收者是 go 语言特有,例如 Java 中指针对应的是 引用传递 。
在接收者这方面可以随意定义想要接收 值还是接收 指针,它并不会改变调用者的调用方式。
例如上面代码中的 traverse() 方法和 print() 方法对于调用者 root 而言不需要任何特殊处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func (node TreeNode) print () {" " )func (node *TreeNode) if node == nil {return print ()func main () var root TreeNode3 }5 , nil , nil }new (TreeNode)2 )4 )
包和封装
封装
名字一般使用 CamelCase(大驼峰,具体可参见:camelCase_百度百科 )。
首字母大写表示:public(类比Java中的修饰符)。
首字母小写表示:private(同上)。
上面的 public 和 private 是针对于 package(包)而言的。
包
每个目录一个包
包名可以和目录名不一样
每个目录只能有一个包
main 包包含可执行入口
为结构定义的方法必须放在同一个包内
可以是不同文件
扩展已有类型
定义别名
使用组合
使用内嵌来扩展已有类型(单独章节介绍)
组合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package mainimport ("fmt" type Node struct {int func (node Node) print () {"[node-print]" , node.Value, " " )type myNode struct {func (node *myNode) print () {"[myNode-print]" , node.node.Value, " " )func main () var root Node3 }5 , nil , nil }new (Node)print ()print ()
运行结果为:
组合的结构内部不一定是指针,结合实际情况处理。
别名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package mainimport ("fmt" type Queue []int func (q *Queue) int ) {append (*q, v)func (q *Queue) int {0 ]1 :]return headfunc (q *Queue) bool {return len (*q) == 0 func main () var q Queue1 )2 )3 )4 )1 }
运行结果为:
使用内嵌来扩展已有类型
修改上面组合方式的Node代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package mainimport ("fmt" type Node struct {int func (node Node) print () {"[node-print]" , node.Value, " " )type myNode struct {func (node *myNode) print () {"[myNode-Node-print]" , node.Node.Value, " " )"[myNode-print]" , node.Value, " " )func main () var root Node3 }5 , nil , nil }new (Node)print ()print ()
注意 func (node *myNode) print()方法和 type myNode struct包含的内容。
它由原来的 node *Node 变为 *Node。
对应的使用可以有两种方式:
使用对象.Node 内嵌类型的首字母
省略对象内嵌类型,直接.对应的方法调用
继承
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package mainimport ("fmt" type Node struct {int func (node Node) print () {"[node-print]" , node.Value, " " )type myNode struct {func (node *myNode) print () {"[myNode-Node-print]" , node.Node.Value, " " )"[myNode-print]" , node.Value, " " )func main () 3 }}5 , nil , nil }new (Node)print ()print ()print ()print ()
其实就是 组合 的语法糖。
注意:只能在定义方法向上面那样取巧,不能实现更多的继承特性。比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package mainimport ("fmt" type Node struct {int func (node Node) print () {"[node-print]" , node.Value, " " )type myNode struct {func (node *myNode) print () {"[myNode-Node-print]" , node.Node.Value, " " )"[myNode-print]" , node.Value, " " )func main () var root *Node3 }}print ()
是不被支持的。
运行会提示报错:
总结
如何扩充系统类型或者别人的类型:
定义别名:最简单
使用组合:最常用
使用内嵌:省下许多代码
Go语言的依赖管理
依赖管理
GOPATH 和 GOVENDOR
GOPATH
默认在:
Windows:%USER%\go
Unix, Linux:~/go
GOPATH 需要手动指定,但是 GOPATH 不能管理同一个包在多个项目中的不同版本的情况。
VENDOR
每个项目有自己的 vendor 目录,用来存放第三方库,就可以很好的解决同一个包在多个项目中不同版本的情况。
GOPATH 和 GOVENDOR 在 Golang 中的优先级为:
GOVENDOR
GOROOT
GOPATH
注意:使用 GOPATH 需要 GO111MODULE = off,并且代理 GOPROXY 不会生效。
go mod 的使用
【推荐】方式一、go get
这里以 Github 上的 uber-go/zap 为例,确保 GO111MODULE = on,执行命令:
1 go get -u go .uber.org/zap
拉下来的包默认就是最新版本,且拉下来的包保存在 %PATH%/pkg/mod 下(Windows是这样,其他的也是类似,在 go env 的 GOPATH 目录下的 pkg/mod)。
方式二、import
还可以直接在代码的 import 关键字内键入需要的包地址即可,例如:
1 2 3 4 5 6 package mainimport ("github.com/gin-gonic/gin" "go.uber.org/zap"
当项目启动会自己去拉取对应的包。
indirect
go.mod 文件出现 packageDomain/packageName v0.0.1 // indirect 这种不用处理,当项目中引用到了对应的包会自动消失,不要手动修改。
获取指定版本
不要修改 go.mod 中的版本号,而是使用 go get -u packageDomain/packageName@version 来获取指定包的指定版本。
清洁(Clean)
执行命令:
即可。
更新所有依赖到 go.mod
执行命令:
即可。
生成 go.mod 文件
执行命令:
按照提示操作即可。